テキストマイニング画面
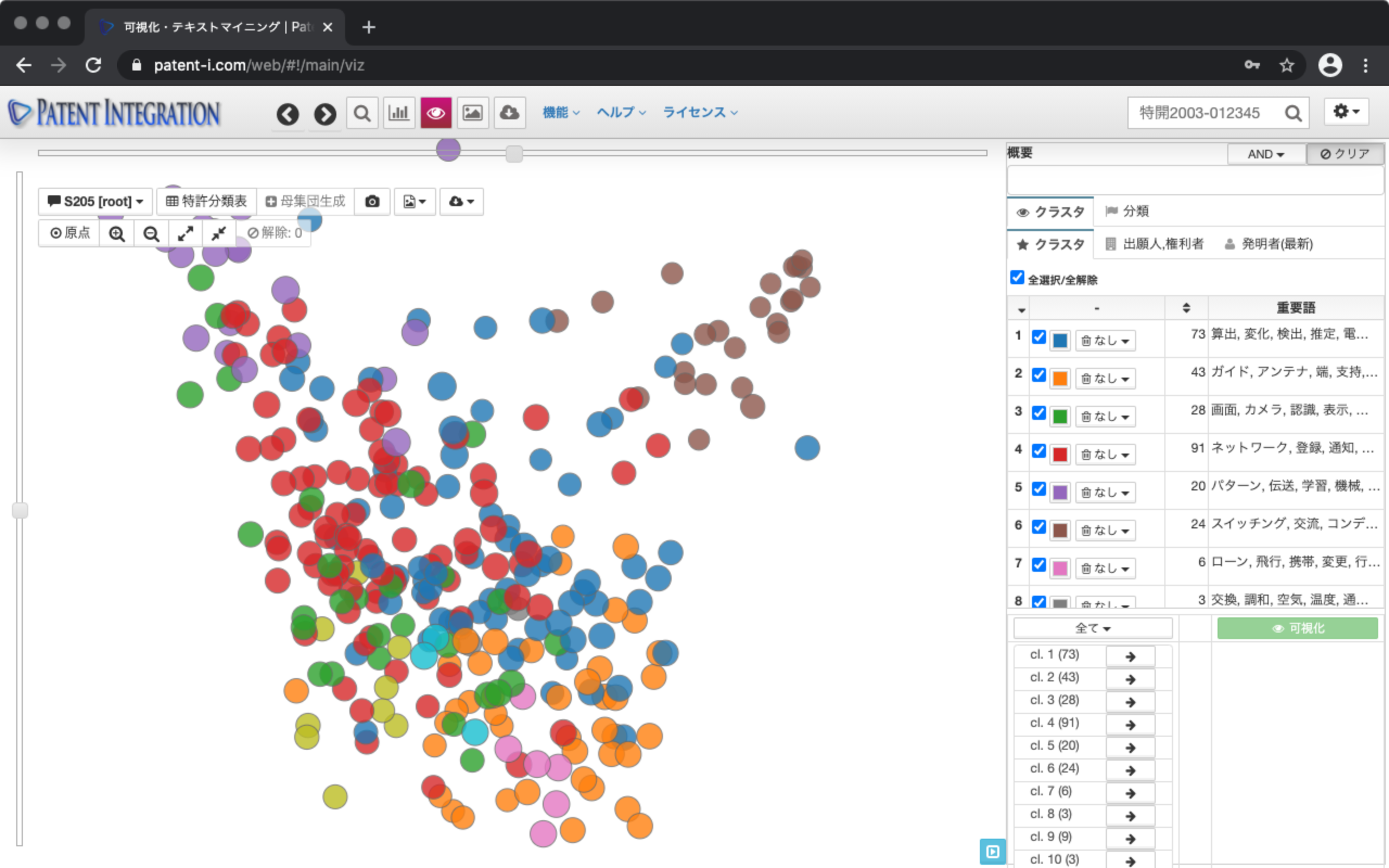
解析処理が完了すると、解析対象の特許集合に対してテキストマイニング処理が行われ、検索集合が視覚的に可視化され表示されます。可視化結果では、各ドット1つ1つが特許に対応しており、文書の類似度に基づくクラスタリングが行われます。クラスタリング結果は画面右側の操作パネルに表示され、各クラスタの重要語を確認することで、各クラスタがどのような技術に関するクラスタであるか理解するためのヒントが得られます。
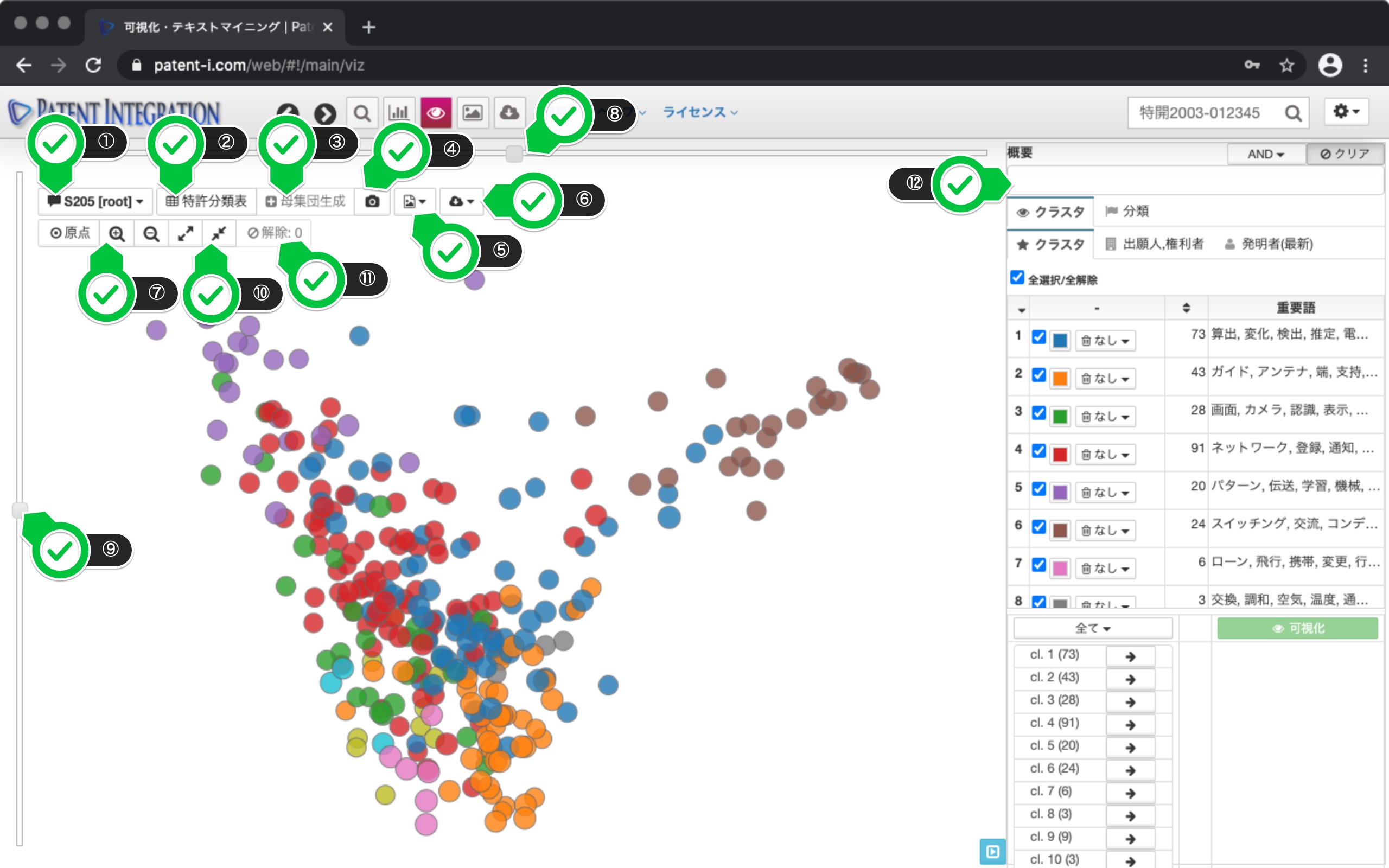
表示画面では類似する特許(ドット)ほど近くに配置され視覚的に技術集合を把握することができます。これにより、分析対象の特許検索集合にどのような観点の特許文献が含まれているか直感的に理解することができます。
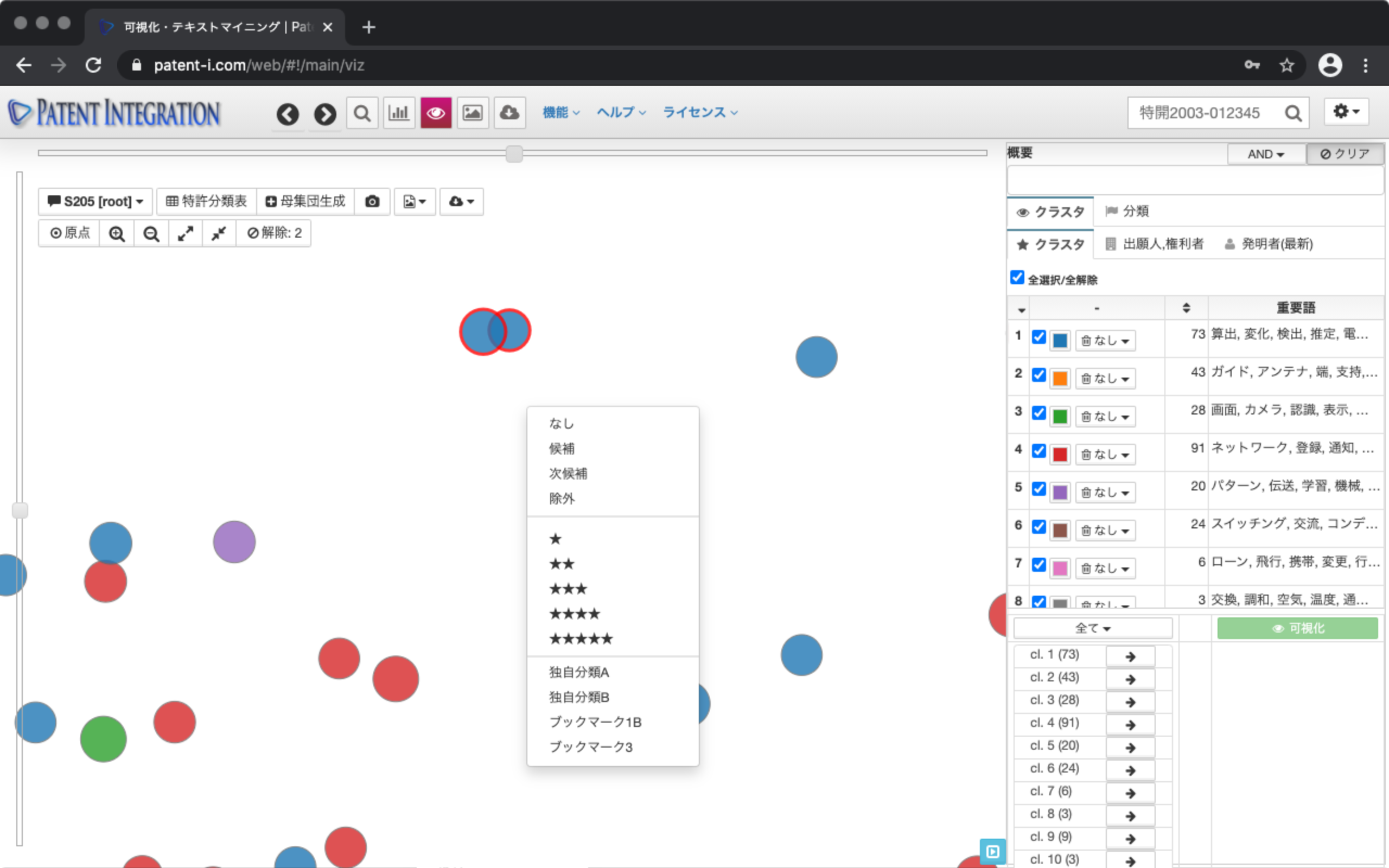
可視化されたドット上はシフトキーを押しながらドラッグ&ドロップすることにより選択することができます。画面上で右クリックをすると、しおり、レーティング、メモ、特許ブックマークなどの ユーザ評価を付与することができます。これにより、特許集合を資格的に確認しながら文献のスクリーニング作業を行うことができます。
特許テキストマイニング画面のユーザインタフェースを以下に示します。
| ① メモボタン | 可視化結果にメモを記録することができます。特許分析作業を通じて、気づいた点などメモしておきます。なお、このボタンには検索集合のIDおよび、可視化結果のIDが表示されます。記録されたメモは検索結果コントロールの履歴管理( 特許検索結果コントロール)から確認できます。 |
| ② 特許分類表( 特許検索結果コントロール) | 可視化されたドット(各特許)上で右クリックすることにより各特許文献に ユーザ評価を付与することができます。しおりを設定した特許文献に対して特許分類表( 特許検索結果コントロール)を適用することで重要特許分類を特定することができます。 |
| ③ 母集団生成 | 可視化されたドット(各特許)は、シフトキーを押しながらドラッグ&ドロップすることにより複数のドットを選択することができます。また、個別ドットをコントロールキーを押しながらクリックすることにより選択されたドットを追加することもできます。 母集団生成ボタンをクリックすると、選択された特許文献に基づき新たな検索集合を作成することができます。作成された検索集合は 特許検索機能の特許検索結果エリアに自動的に追加されます。なお、選択状態は以下の解除ボタンにより解除することができます。 |
| ④ サムネイル | 現在の検索集合において過去に作成した可視化結果をサムネイル形式で一覧表示させることができます。クリックすることで可視化結果を再描画させることができます。また、メモを確認・記録することもできます。 |
| ⑤ イメージ ダウンロード | 作成したグラフ(チャート)を、PNG、JPG、PDF、SVG形式でダウンロードします。作成したグラフを報告資料などで利用する場合に利用します。 |
| ⑥ データダウンロード | 集計したデータを、クリップボードへコピーしたり、TSV(タブ区切りテキスト)、CSV形式(カンマ区切りテキスト)でダウンロードします。データをExcelなどの表計算ソフトで利用する場合に利用します。 |
| ⑦ 原点、拡大・縮小 | 原点ボタンをクリックすることで、可視化結果の表示を原点に戻します。拡大・縮小ボタンにより可視化結果をズームすることができます。 なお、描画された可視化結果はマウスによるドラッグ&ドロップおよびスクロールにより拡大・縮小を行うことができます。 |
| ⑧ 時系列スライダ | 可視化画面では出願日が新しいものほど手前にプロットされており、出願日が古いものが奥側に三次元的に可視化されています。上部のスライダを操作することにより、集合を側面、つまり出願日順に並べることができます。 これにより技術ごとの出願トレンド、出願件数の推移などを資格的に確認することができます。 |
| ⑨ 回転スライダ | 可視化結果を回転させることができます。時系列スライダを利用して可視化結果を側面から見た際に、奥の方にある特許を見たい場合に利用します。 |
| ⑩ 時系列 拡大・縮小 | 時系列方向のドットの間隔(出願日の間隔)を、広げたり狭めたりできます。出願が密な領域の構造をより詳しくみたい場合には出願日の間隔を広げることでより詳細に特許出願の分布を把握することができます。 |
| ⑪ 解除ボタン | 解除ボタンをクリックすることにより、ドットの選択状態を解除することができます。 |
| ⑫ 操作パネル | 可視化結果に対して、クラスタや出願人ごとに配色したり、キーワード、特許分類ごとの可視化結果における分布を確認することができます。詳細な説明は次のセクションを確認してください。 |
特許テキストマイニング画面・ユーザインタフェース
特許テキストマイニング機能の基本的な操作方法を以下に説明します。
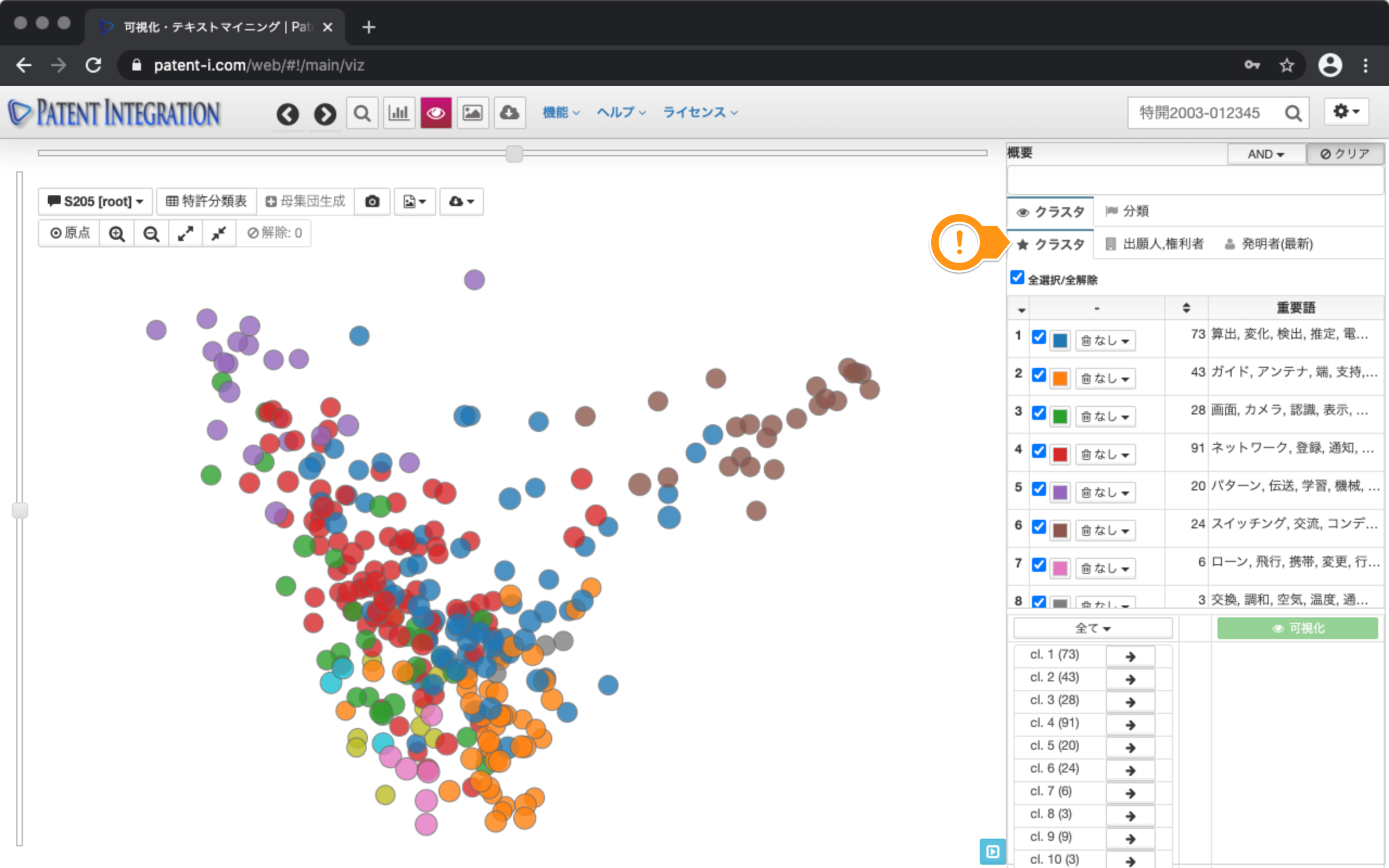
1.クラスタの確認
画面右側の操作パネルにはクラスタごとの色に対応した、クラスタの説明が一覧表示されます。クラスタの右横には各クラスタの重要語が表示されます。この重要語は、特許集合の分析軸、つまりこの集合がどのような技術から成り立っているのか解釈するためのヒントが得られます。
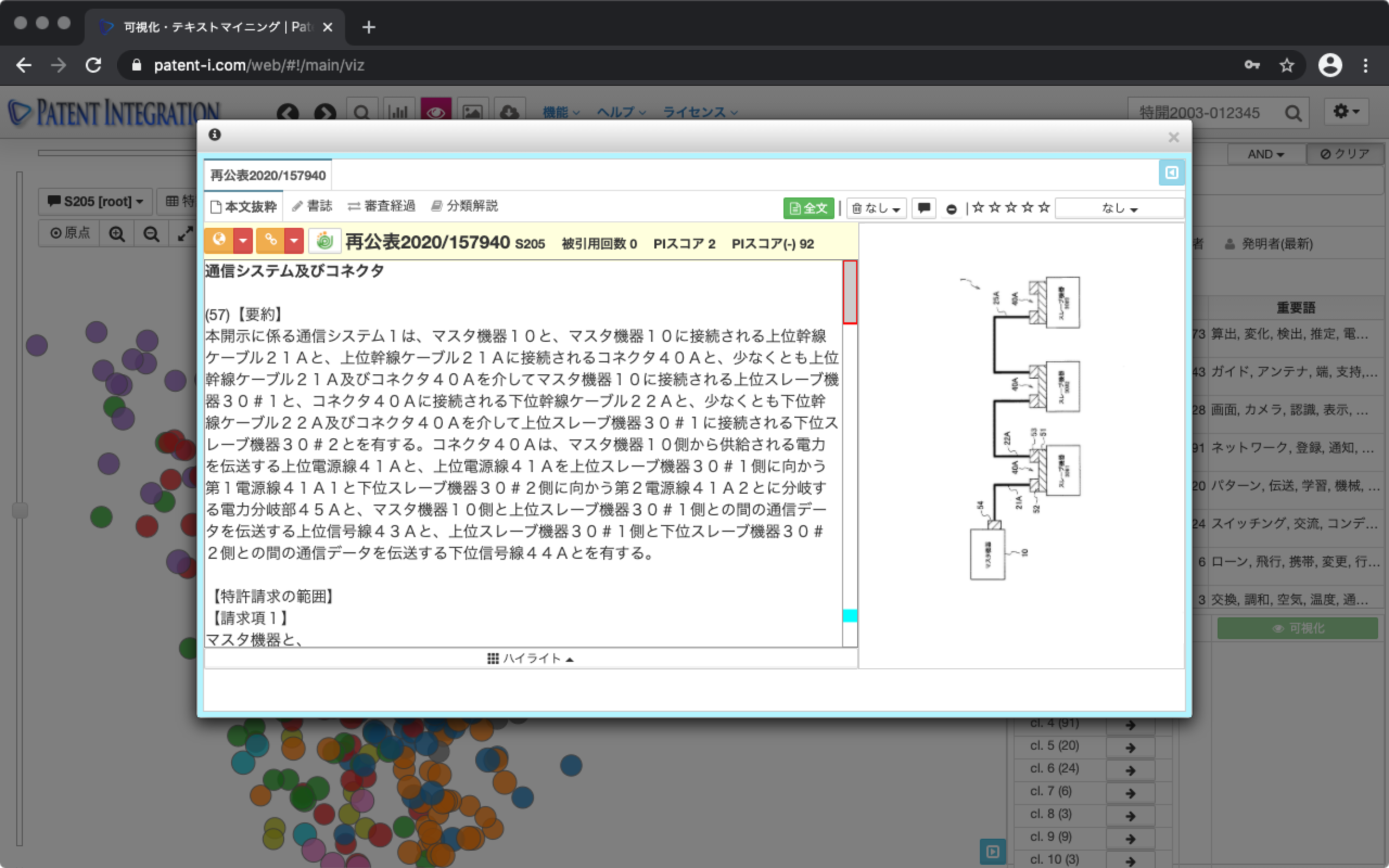
2.特許公報の内容確認
ドットをクリックすることで、各特許を抄録形式( 抄録表示機能(個別案件))で閲覧することができます。
3.時系列の観点から眺める
可視化画面では出願日が新しいものほど手前にプロットされており、出願日が古いものが奥側に三次元的に可視化されています。上部のスライダを操作することにより、集合を側面、つまり出願日順に並べることができます。この場合、左側には出願日の古い特許が位置し、右側には出願日が新しい特許が位置することになります。原点ボタンをクリックすることにより表示を初期状態に戻すことができます。

4.特許集合の分布確認
右側のコントロールエリアでは、この可視化結果にどのような特許がそれぞれ位置付けられているのか確認することができます。例えば、分類タブをクリックし、重要語のタブをクリックすると重要語が一覧表示されます。電力と入力することで、重要語を絞り込むことができます。
次に、バッテリーというキーワードをクリックすると、当該キーワードを含む特許にフラグを表示させることができます。
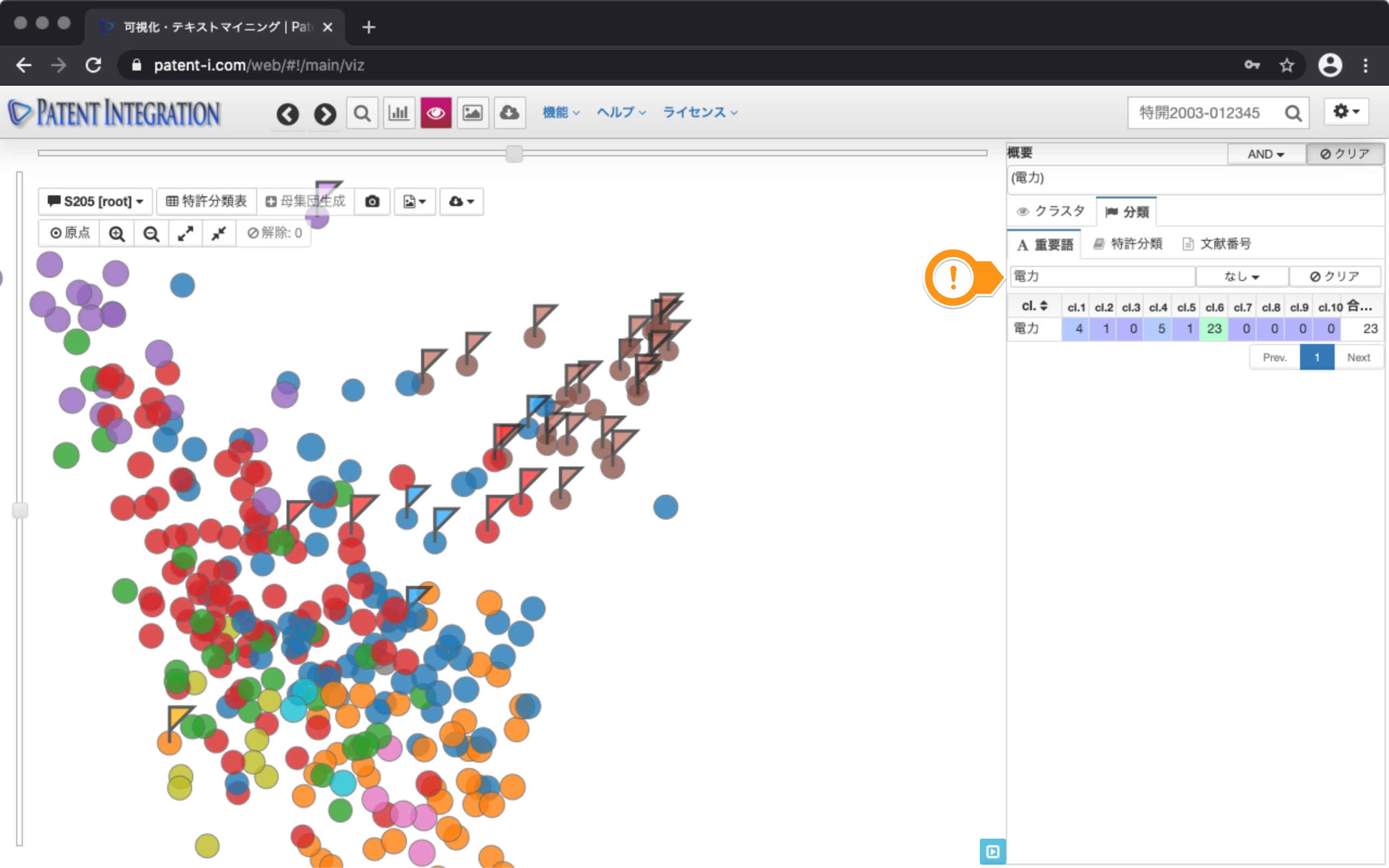
これにより、特許検索集合でバッテリーが含まれる特許を特定することができます。これにより、紫色、赤色、ピンク色、水色のクラスタがバッテリ関連のクラスタであることを確認することができ、各特許の技術ポジションを大まかに把握することができます。